
How to Postgres on Kubernetes, deel 1
Verschillen tussen Docker en Kubernetes In deze blog ga ik er vanuit dat je al een werkende Kubernetes-setup hebt. Of…

In deel een liet Nathan Koopmans, Cloud platform-engineer bij OptimaData, zien hoe je een simpele plain PostgreSQL setup maakt. Ondanks dat dit prima werkt, wil je toch graag meer zekerheid qua data. Daarom kijken we in dit tweede deel naar de CloudNativePG-operator voor Kubernetes.

Een van de grootste voordelen aan het gebruik van de CloudNativePG-operator is dat het je veel zaken uit handen neemt. Zo gaat een failover automatisch, het beheert zijn eigen volumeclaims en heeft een ingebouwde exporter voor Prometheus-metrics.
Wanneer je de deployment schaalt, worden ook automatisch de pods en gerelateerde zaken met betrekking tot de database uitgebreid. Deze zaken mis je bij een opzet zoals in deel een besproken. Aangezien de CloudNativePG-operator kosteloos te gebruiken is, kan dit ook toegepast worden in hobby- en kleinzakelijke omgevingen, waar high availability gewenst is, maar de kosten beperkt moeten blijven.
Om te beginnen gaan we de laatste versie van de operator downloaden. Deze is te vinden op de Github-pagina van CloudNativePG.
Klink aan de rechterkant op de versie onder Releases.
Op de nieuwe pagina zie je allemaal bugfixes en verbeteringen. Scroll naar onderen naar het kopje Assets. Zoek hier naar de .yaml file.
Belangrijke opmerking:
We zitten inmiddels in versie 1.28. Ten tijde van deze “How-to” was dat 1.20. Lees dus overal waar 1.20 wordt geschreven de meest recente versie.
In het geval van deze how-to is dat cnpg-1.20.1.yaml. Maar je kan dus net zo goed een recentere versie toepassen. Met wget kunnen we deze file binnen halen:
wget https://github.com/cloudnative-pg/cloudnative-pg/releases/download/v1.20.1/cnpg-1.20.1.yaml
Je kan dit ook direct toepassen door i.p.v. wget het commando kubectl apply -f te gebruiken, echter vind ik het zelf altijd prettig de file ter controle offline te hebben staan alvorens ik het toepas.
Na het downloaden van de yaml file moet deze nog toegepast worden. Dat doe je op de volgende manier:
kubectl apply -f cnpg-1.20.1.yaml
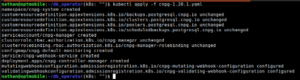
In mijn screenshot zie je een aantal roles en CRD’s (customresourcedefinition) op unchanges staan. Dat is het gevolg van een eerdere installatie van de cnpg-1.20.1.yaml. Bij jou kan het dus iets afwijken van mijn screenshot. Bovenaan de output zie je dat er een namespace is aangemaakt genaamd cnpg-system. In deze namespace staan de operator POD en andere operator gerelateerde zaken.
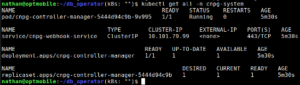
Voer het command kubectl get all -n cnpg-system uit om te zien wat er allemaal in de namespace aanwezig is.
Nu we de operator hebben geïnstalleerd, kunnen we de commandline-plugin installeren. Hiermee kan je, als we straks ons cluster hebben uitgerold, extra informatie opvragen. In de documentatie kunnen we onder “CloudNativePG Plugin” vinden hoe we de plugin moeten installeren:
curl -sSfL
https://github.com/cloudnative-pg/cloudnative-pg/raw/main/hack/install-cnpg-plugin.sh |
sudo sh -s -- -b /usr/local/bin
Na het installeren van de plugin kan je met kubectl cnpg status clusternaam -n namespace de status van het cluster opvragen. In een latere stap zal ik de output laten zien.
Nu alle voorbereidingen zijn gedaan, kunnen we een cluster gaan maken. In de documentatie van CloudNativePG wordt een voorbeeld gegeven voor een cluster middels cluster-example.yaml:
# Example of PostgreSQL cluster
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-example
spec:
instances: 3
# Example of rolling update strategy:
# - unsupervised: automated update of the primary once all
# replicas have been upgraded (default)
# - supervised: requires manual supervision to perform
# the switchover of the primary
primaryUpdateStrategy: unsupervised
# Require 1Gi of space
storage:
size: 1Gi
We passen dit iets aan om het voor ons werkend te maken. Let op: controleer wat jouw storageclass is en hoeveel ruimte je toe wil wijzen. In mijn geval heb ik voor longhorn gekozen, aangezien dat mijn gebruikte storage-oplossing is en 5Gi ruimte, omdat ik voldoende heb. Met kubectl get sc kan je zien welke storageclasses jij tot je beschikking hebt.

Uiteindelijk ziet mijn example-cluster.yaml er zo uit:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: test-cluster
labels:
env: database
spec:
imageName: ghcr.io/cloudnative-pg/postgresql:13.6
primaryUpdateStrategy: supervised
instances: 3
storage:
size: 5Gi
pvcTemplate:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: longhorn
volumeMode: Filesystem
postgresql:
parameters:
log_line_prefix: '%t [%p]: [%l-1] user=%u,db=%d,app=%a,client=%h '
pg_hba:
- host all all 0.0.0.0/0 md5
Het cluster wil in een eigen namespace draaien, daarom maak ik eerst een nieuwe namespace aan:
kubectl create ns testcluster

Dan kunnen we nu de cluster-example.yaml toe gaan passen:
kubectl apply -f cluster-example.yaml -n testcluster
![]()
Om in de gaten te houden wat er allemaal aangemaakt wordt, kan je het commando kubectl get all -n testcluster gebruiken.
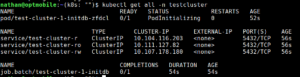
Je kan het commando een aantal keer uitvoeren, je kan er echter ook watch voor plaatsen. Met het programma watch wordt het scherm elke 2 seconden ververst. Het commando ziet er dan als volgt uit watch kubectl get all -n testcluster of wanneer je alleen de pods in de gaten wil houden watch kubectl get pods -n testcluster
Na even geduld te hebben zijn er 3 pods in de running state:
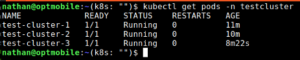
Aangezien het een nieuw opgezet cluster is, gaan we er gemakshalve vanuit dat test-cluster-1 de master / primary is en de 2 en 3 slave. Dit kunnen we controleren met de plugin die we een paar stappen terug hebben geïnstalleerd, namelijk de cnpg-plugin.
kubectl cnpg status test-cluster -n testcluster
Je krijgt dan de volgende output te zien:
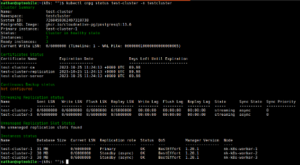
Dit bevestigt het vermoeden dat test-cluster-1 inderdaad de primary is. We hebben drie instances, alle drie zijn ready en het cluster is healthy. Dan is het nu tijd om te kijken of we verbinding kunnen maken.
De opzet met CloudNativePG vraagt om een andere manier om verbinding te maken met de database binnen de pod. Om te beginnen moeten we het wachtwoord achterhalen dat aan de postgres-gebruiker is toegekend. Dit kan met het volgende commando:
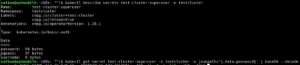
kubectl get secrets -n testcluster
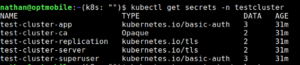
Hier zien we een secret genaamd test-cluster-superuser, dit is de secret waar we het wachtwoord uit moeten extracten. De velden die in de secret zitten kan je opvragen met kubectl describe secrets test-cluster-superuser -n testcluster we zien dan het passwordveld. Nu gaan we het wachtwoord daar uithalen en leesbaar maken:
kubectl get secret test-cluster-superuser -n testcluster -o jsonpath='{.data.password}' | base64 --decode
Het wachtwoord laat ik hier niet zien. Het is een lange reeks aan cijfers en letters. Kopieer deze naar een apart document, zodat we het zo makkelijk kunnen gebruiken. Wat we nu gaan doen is een port-forward starten naar de pod welke primary is. Zo kunnen we zien dat de database werkt.
kubectl port-forward -n testcluster test-cluster-1 5432:5432 &
Het & teken achteraan voert de taak in de achtergrond uit. Zo kunnen we in hetzelfde venster blijven werken. In deel een liet ik al het gebruik van de psql-client zien (psql). Echter in plaats van op het node IP-adres verbinding te maken, doen we dat nu op het localhost IP-adres, namelijk 127.0.0.1. Dit wordt geregeld door de port-forward.
De standaardgebruiker is postgres, het wachtwoord hebben we in een apart document gezet en dat hebben we nu nodig.
psql -h 127.0.0.1 -U postgres
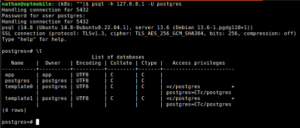
Met l kan je de databases zien. Nu we ook daadwerkelijk informatie terug krijgen, weten we dat het naar behoren werkt.
In deel een en deel twee heb ik laten zien hoe je PostgreSQL binnen Kubernetes kan gebruiken. Ik ga ervan uit dat je binnen het Kubernetes-cluster al aan de beveiliging hebt gedacht, zoals per pod de securityContext inregelen. Dat is buiten de scope van deze uitlegserie. Met betrekking tot de operator is de securityContext en de RBAC (Role-Based Access Control) al goed geregeld. Meer informatie over de securityContext vind je in de Kubernetes-documentatie.
Deze blog is een twee luik serie. Lees hieronder de vorige blogpost.
In de voorbeelden hebben we een eenvoudige setup van PostgreSQL gedaan. Er is niets aan de overige configuratie van parameters gedaan en daar is veel te halen qua performance. Het is aan te raden altijd een expert mee te laten kijken zodat jouw data of die van jouw klant veilig staat en snel beschikbaar is.
Ben je bezig met PostgreSQL en Kubernetes of zou je de stap willen maken? Wij hebben al meerdere PostgreSQL-omgevingen in combinatie met Kubernetes opgezet en in beheer. Neem gerust contact met ons op. Wij staan voor je klaar via 0353690307 of informatie@optimadata.nl




