

Databaserecovery. Heb jij al getest?
Tapes Iedereen kent het wel, het wisselen van tapes en deze afvoeren naar een veilige, off-site, omgeving of in een…

Intra-query parallelisme deadlocks kunnen een aanzienlijke invloed hebben op de prestaties van een database. Deze complexe problemen treden op wanneer SQL Server parallelle verwerking van een query probeert uit te voeren, maar hierbij herhaaldelijk vastloopt, waardoor er steeds weer een stap terug moet worden gedaan. In deze blog vertelt Mark van der Haar, databaseconsultant bij OptimaData, over de oorzaken van deze deadlocks, hoe ze kunnen worden herkend en welke stappen kunnen worden ondernomen om ze op te lossen.

Enkele jaren terug kreeg ik de vraag de prestaties van verschillende queries te onderzoeken. Deze queries waren bedoeld voor het ophalen van gegevens voor flinke rapporten in business-objects. Na een upgrade waren de doorlooptijden ernstig verslechterd. Ik wilde graag de requirements weten, maar SAP deelt die alleen deelt met geregistreerde accounts, waar wij geen toegang toe hebben. Na grondig onderzoek ontdekte ik dat intra-query parallelism deadlocks de hoofdoorzaak waren van dit prestatieprobleem. Een query die een half uur in beslag nam, wisten we terug te brengen naar slechts vijf minuten. Hoewel deze vorm van deadlocking doorgaans de prestaties negatief beïnvloedt, is dit zelden zo extreem als in dit specifieke geval. Bij het beheer van nieuwe instanties merk ik regelmatig dit soort deadlocks op. Onlangs heb ik weer een ervaring gehad, waarbij de querytijd teruggebracht zou kunnen worden van elf seconden naar vijf. Maar er waren geen klachten van gebruikers, dus zijn we het traject van de applicatie aanpassing maar niet gestart.
Wanneer SQL Server een query parallel uitvoert, worden er zowel producer- als consumer-threads gestart. De producers maken pakketten en sturen deze naar een buffer, terwijl de Exchange-operator deze buffer regelt. Aan de andere kant lezen de consumers de data uit de pakketten in de buffer. Dit proces kan leiden tot wachttijden, zoals wanneer de buffer leeg is (consumers moeten wachten) of vol (producers moeten wachten). Deze wachttijden resulteren vaak in CXPACKET- en CXCONSUMER-waittypes. Soms raakt dit proces echter vast in een deadlock. In het verleden resulteerde dit in een foutmelding, maar tegenwoordig lost SQL Server het op met een Exchange Spill. Hoewel dit een oplossing lijkt, kan het ervoor zorgen dat intra-query parallelism deadlocks onopgemerkt blijven. Op SQLShack vind je een uitgebreid artikel over parallelisme: “Troubleshooting the CXPACKET wait type in SQL Server”.
Het herkennen van intra-query parallelisme deadlocks kan een uitdaging zijn, maar er zijn verschillende indicatoren die kunnen wijzen op de aanwezigheid ervan. Wanneer een query vastloopt door deze deadlocks, ontstaat er aanzienlijke wait-time, vaak aangegeven met de wait types CXCONSUMER en CXPACKET. Normale parallelle queries zouden slechts een fractie van hun wait-time aan deze wait types moeten besteden. Het gebruik van monitoring-tools zoals check_mk of Redgate kan helpen bij het identificeren van deze problemen. Hier een voorbeeld van check_mk:
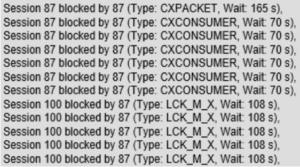
In de Activity Monitor kun je sessies zien die zichzelf blokkeren, wat een indicatie kan zijn van intra-query parallelisme deadlocks. Hieronder zie je bijvoorbeeld sessie 79 die zichzelf blokkeert.

Een andere plek waar je intra-query deadlocks goed kunt waarnemen, is in de DMV’s (Dynamic Management Views): sys.dm_exec_query_stats, sys.dm_exec_procedure_stats en sys.dm_exec_trigger_stats. Deze views bevatten kolommen zoals total_spills, last_spills, max_spills en min_spills. Echter, niet veel databasebeheerders zullen hier dagelijks naar kijken. Bovendien zijn deze kolommen pas toegevoegd in SQL Server 2016 SP2 en SQL Server 2017 CU3. Dit is een aanvullende reden om je SQL Server-instantie up-to-date te houden.
Het aanpakken van intra-query parallelisme deadlocks kan een uitdaging zijn, maar er zijn verschillende benaderingen die kunnen worden toegepast. Een eerste stap is om het uitvoeringsplan van de query grondig te analyseren om mogelijke optimalisaties te identificeren, zoals het toevoegen van indexen om de query sneller te laten verlopen. Het verminderen van de afhankelijkheid van parallelle verwerking kan een effectieve manier zijn om dergelijke deadlocks te voorkomen.
Een meer drastische aanpak is het expliciet aangeven van de maximale graad van parallelisme (MAXDOP) door de query een hint mee te geven met OPTION (MAXDOP 1). Het kan ook nuttig zijn om eerst te experimenteren met lagere waarden voor MAXDOP, zoals 4 of 2, op grotere systemen. Echter, het is belangrijk om niet de MAXDOP van de gehele SQL Server-instantie naar 1 te verlagen, aangezien dit de prestaties van queries die juist baat hebben bij parallelle verwerking kan verminderen.
In sommige gevallen kan het gebruik van trace flags ook een effectieve oplossing zijn. Bijvoorbeeld, voor de business-objects-query was het inschakelen van trace flags die parallelle uitvoering van queries voor de gehele instantie uitschakelen de oplossing.
Een andere mogelijke aanpak is het aanpassen van de wachttijd op deadlocks met behulp van SET LOCK_TIMEOUT 10. Hierdoor verkort je de tijd die nodig is om een deadlock te detecteren, waardoor de query sneller kan worden voltooid. Daarmee los je echter het onderliggende probleem niet op.
Wil je voorkomen dat intra-query parallelisme deadlocks je databaseprestaties beïnvloeden? Wil je je geen zorgen maken over de prestatie van je databases? Wij helpen je graag je databases onder controle te houden. Neem gerust contact op. We leren je graag kennen.




