

Databaserecovery. Have you tested yet?
Tapes Everyone is familiar with changing tapes and disposing of them to a secure, off-site, environment or in a vault.…

Intra-query parallelism deadlocks can have a significant impact on database performance. These complex problems occur when SQL Server tries to perform parallel processing of a query but repeatedly crashes in the process, requiring a step back over and over again. In this blog, Mark van der Haar, database consultant at OptimaData, talks about the causes of these deadlocks, how they can be recognized and what steps can be taken to resolve them.

Several years back, I was asked to investigate the performance of several queries. These queries were for retrieving data for hefty reports in business objects. After an upgrade, the processing times had seriously deteriorated. I wanted to know the requirements, but SAP only shares them with registered accounts, which we don’t have access to.
After thorough investigation, I discovered that intra-query parallelism deadlocks were the root cause of this performance problem.
We managed to reduce a query that took half an hour to just five minutes. While this type of deadlocking usually affects performance negatively, it is rarely as extreme as in this particular case. When managing new instances, I frequently notice deadlocks of this type. I recently had another experience where the query time could be reduced from eleven seconds to five. But there were no complaints from users, so we just didn’t start the application customization process.
When SQL Server executes a query in parallel, both producer and consumer threads are started. The producers create packets and send them to a buffer, while the Exchange operator controls this buffer. On the other hand, the consumers read the data from the packets into the buffer. This process can result in wait times, such as when the buffer is empty (consumers must wait) or full (producers must wait). These wait times often result in CXPACKET and CXCONSUMER wait types.
Sometimes, however, this process gets stuck in deadlock. In the past, this resulted in an error message, but today SQL Server resolves it with an Exchange Spill. While this seems like a solution, it can cause intra-query parallelism deadlocks to go undetected. On SQLShack, you can find a comprehensive article on parallelism: “Troubleshooting the CXPACKET wait type in SQL Server.”
Recognizing intra-query parallelism deadlocks can be challenging, but there are several indicators that can indicate their presence. When a query crashes due to these deadlocks, significant wait-time occurs, often indicated by the wait types CXCONSUMER and CXPACKET. Normal parallel queries should spend only a fraction of their wait-time on these wait types. Using monitoring tools such as check_mk or Redgate can help identify these problems. Here is an example of check_mk:
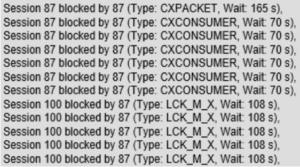
In the Activity Monitor, you can see sessions blocking themselves, which can be an indication of intra-query parallelism deadlocks. For example, below you can see session 79 blocking itself.
Another place where you can properly observe intra-query deadlocks is in the DMVs (Dynamic Management Views): sys.dm_exec_query_stats, sys.dm_exec_procedure_stats and sys.dm_exec_trigger_stats. These views contain columns such as total_spills, last_spills, max_spills and min_spills. However, not many database administrators will look at these on a daily basis. Moreover, these columns were only added in SQL Server 2016 SP2 and SQL Server 2017 CU3. This is an additional reason to keep your SQL Server instance up-to-date.
Addressing intra-query parallelism deadlocks can be a challenge, but there are several approaches that can be taken. A first step is to thoroughly analyze the query execution plan to identify possible optimizations, such as adding indexes to make the query faster. Reducing reliance on parallel processing can be an effective way to avoid such deadlocks.
A more drastic approach is to explicitly specify the maximum degree of parallelism (MAXDOP) by giving the query a hint with OPTION (MAXDOP 1). It may also be useful to first experiment with lower values for MAXDOP, such as 4 or 2, on larger systems. However, it is important not to lower the MAXDOP of the entire SQL Server instance to 1, as this can reduce the performance of queries that actually benefit from parallel processing.
In some cases, using trace flags can also be an effective solution. For example, for the business-objects query, enabling trace flags that disable parallel execution of queries for the entire instance was the solution.
Another possible approach is to adjust the wait time on deadlocks using SET LOCK_TIMEOUT 10. This reduces the time it takes to detect a deadlock, allowing the query to complete faster. In doing so, however, you do not solve the underlying problem.
Do you want to prevent intra-query parallelism deadlocks from affecting your database performance? Don’t want to worry about the performance of your databases? We are happy to help you keep your databases under control. Feel free to contact us.




